

Digital Age: Сбогом на Photoshop ? Нов ИИ създава и редактира изображения само с поискване
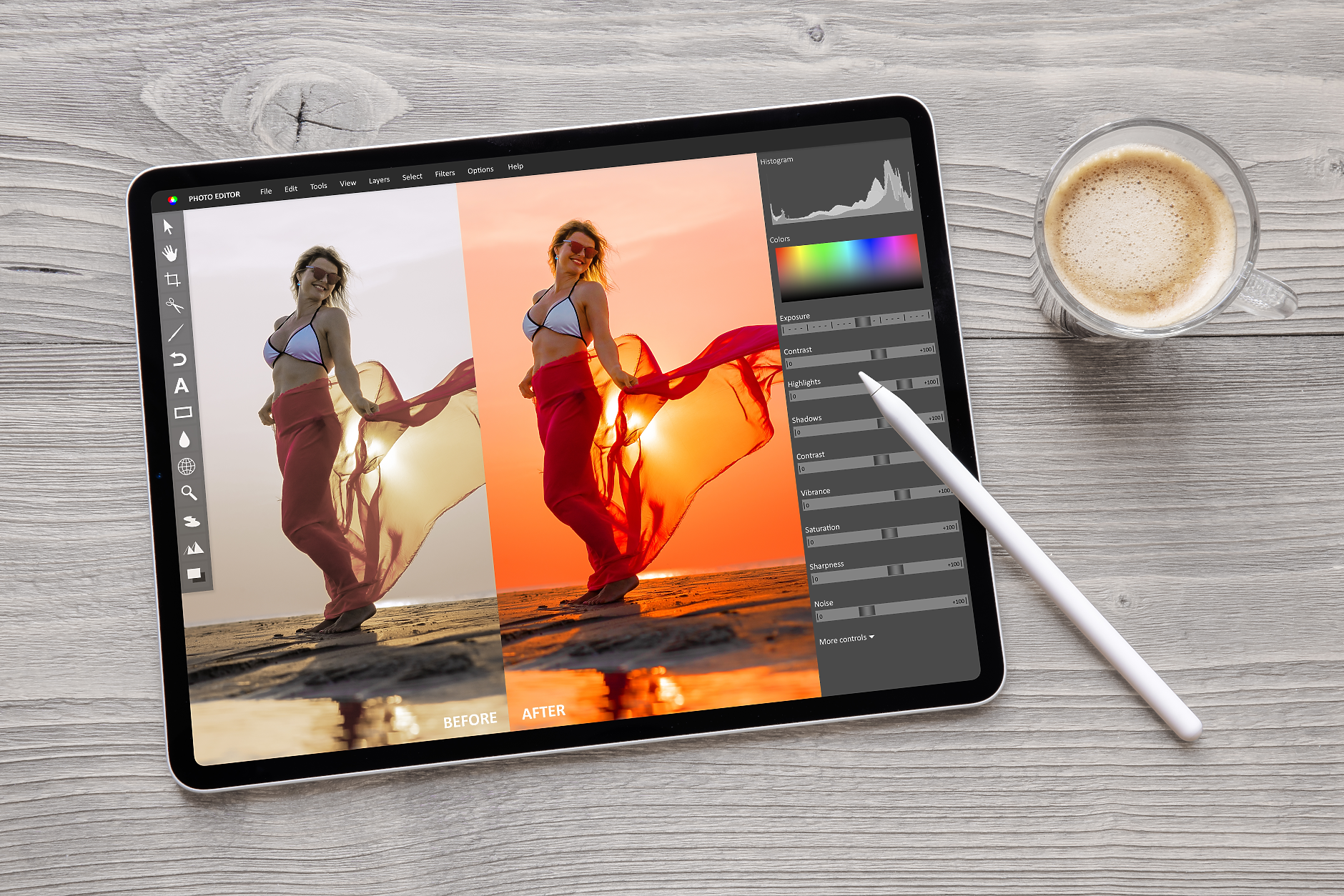
От години Photoshop е нарицателно за редактиране и манипулация на изображения, но с основателна причина - софтуерът на Adobe е едновременно достатъчно комплексен, за да позволи фини настройки, и относително лесен за използване, така че да не бъде бариера дори за начинаещи дигитални редактори.
На пазара обаче вече има нов модел на Google с изкуствен интелект, който може да генерира или редактира изображения толкова лесно, колкото и да създава текст - като част от разговора с чатбота. Резултатите не са перфектни, но е напълно възможно в близко бъдеще всеки да може да манипулира изображения по този начин.
Миналата сряда Google разшири достъпа до естествените възможности за генериране на изображения на Gemini 2.0 Flash, като направи експерименталната функция достъпна за всеки, който използва Google AI Studio. Функцията беше налична още от декември насам, макар ограничена до ограничен група ранни потребители. Днес тя е пълноценна мултимодална технология, която интегрира в един модел на изкуствен интелект вградени възможности за обработка както на текст, така и на изображения.
Новият модел, озаглавен Gemini 2.0 Flash (Image Generation) Experimental, остана донякъде по-слабо забелязан миналата седмица, но през последните няколко дни привлича все повече внимание поради способността му да премахва водни знаци от изображения, макар и с артефакти и намаляване на качеството на изображението.
Това не е единственият трик в ръкава на новия софтуер. Gemini 2.0 Flash може да добавя обекти, да премахва обекти, да променя пейзажа, да променя осветлението, да се опитва да променя ъгъла на изображението, да увеличава или намалява и да извършва други трансформации - всичко това с различна степен на успех в зависимост от обекта, стила и изображението.
За да се справи с това, Google обучи Gemini 2.0 на голям набор от данни с изображения (преобразувани в токени) и текст. „Знанията“ на модела за изображенията заемат същото пространство на невронната мрежа като знанията му за световните понятия от текстови източници, така че той може директно да извежда лексеми на изображения, които се преобразуват обратно в изображения и се подават на потребителя.
Включването на генериране на изображения в ИИ чат само по себе си не е нещо ново – OpenAI интегрира своя генератор на изображения DALL-E 3 в ChatGPT миналия септември и други технологични компании като xAI последваха примера. Досега обаче всеки един от тези асистенти за чат с изкуствен интелект извикваше отделен AI модел, базиран на дифузия (който използва различен принцип на синтез от големите езикови модели), за да генерира изображения, които след това бяха върнати на потребителя в интерфейса за чат. В този случай Gemini 2.0 Flash е както голям езиков модел, така и ИИ генератор на изображения, събрани в една система.
Интересното е, че GPT-4o на OpenAI също може да извежда оригинални изображения (президентът на OpenAI Грег Брок загатна за функцията в един момент в своя публикация в социалната мрежа X миналата година), но тази компания все още не е пуснала истинска мултимодална способност за извеждане на изображения. Една от причините за това вероятно е, че истинският мултимодален генератор на изображения е много скъп от изчислителна гледна точка, тъй като всяко въведено или генерирано изображение е съставено от токени, които стават част от контекста, който преминава през модела на изображението отново и отново с всяка следваща подкана. И предвид изчислителните нужди и размера на данните за обучение, необходими за създаване на наистина визуално изчерпателен мултимодален модел, изходното качество на изображенията все още не е непременно толкова добро, колкото дифузионните модели.
Друга причина, поради която OpenAI се бави с публичния достъп на функцията, може да е свързана с „безопасността“: Подобно на начина, по който мултимодалните модели, обучени на аудио, могат да абсорбират кратък клип от гласа на примерен човек и след това да го имитират безупречно (по този начин работи Разширеният гласов режим на ChatGPT, с клип на гласов актьор, който има правото да имитира), мултимодалните изходни модели на изображение са способни да фалшифицират медийната реалност по сравнително лесен и убедителен начин начин, предвид подходящи данни за обучение и изчисление зад него. С достатъчно добър мултимодален модел потенциално опасните дълбоки фалшификати и фото манипулации могат да станат още по-елементарни за производство, отколкото са сега.
Новата функционалност в действие
И така, какво точно може да направи Gemini 2.0 Flash? По-специално, неговата поддръжка за разговорно редактиране на изображения позволява на потребителите да прецизират итеративно изображения чрез диалог на естествен език в множество последователни подкани. Можете да говорите с него и да му кажете какво искате да добавите, премахнете или промените. Това е несъвършено, но е началото на нов тип естествени възможности за редактиране на изображения в света на технологиите.
Достатъчно е да дадете на Gemini Flash 2.0 набор от свободни команди за редактиране на изображения с изкуствен интелект и програмата запълва фона с най-доброто си предположение. Може да добавите дори такива фини детайли като линиите по екрана на някогашните CRT телевизори, ако решите да създадете изображение на ретро видеоигра. Няма нужда дори от популярни инструменти като от четката за клониране на пиксели на Photoshop.
Накрая, можете да премахнете водни знаци, въпреки че полученото изображение не е близо до разделителната способност или качеството на детайлите на оригинала. В крайна сметка, ако мозъкът ви може да си представи какво представлява едно изображение без воден знак, също може и един ИИ модел. Той запълва пространството на водния знак с най-правдоподобния резултат въз основа на своите данни за обучение.
Като цяло, той не създава изображения с първокласно качество или детайлност, но потребителите буквално не извършват никакво редактиране освен въвеждането на заявки. Понастоящем Adobe Photoshop позволява на потребителите да манипулират изображения с помощта на ИИ синтез въз основа на писмени подкани с Generative Fill, но това не е толкова естествено като това. Можем да предположим, че Adobe ще иска да добави по-разговорен поток за редактиране на изображения с изкуствен интелект като този в бъдеще.
Мултимодалното създаване на изображения разкрива нови възможности
Наличието на истински мултимодален генератор отваря интересни нови възможности в чатботовете. Например, Gemini 2.0 Flash може да играе интерактивни графични игри или да генерира истории с последователни илюстрации, поддържайки персонажа и непрекъснатостта на настройките в множество изображения. Далеч не е перфектно, но последователността на персонажите е нова възможност в ИИ асистентите.
Изобразяването на текст представлява друга потенциална сила на модела. Google твърди, че вътрешните бенчмаркове показват, че Gemini 2.0 Flash се представя по-добре от "водещите конкурентни модели" при генериране на изображения, съдържащи текст, което го прави потенциално подходящ за създаване на съдържание с интегриран текст. Засега практическите резултати не са толкова вълнуващи, но поне са четливи.
Въпреки недостатъците на Gemini 2.0 Flash досега, появата на истински мултимодален генератор на изображение изглежда като забележителен момент в историята на ИИ поради това, което предполага, ако технологията продължи да се подобрява. Ако си представите бъдеще, да кажем след 10 години, в което достатъчно сложен ИИ модел може да генерира всякакъв тип медии в реално време – текст, изображения, аудио, видео, 3D графики, 3D отпечатани физически обекти и интерактивни преживявания – вие всъщност имате холограма, но без репликация на материята.
Връщайки се към реалността, все още е рано за "масовизацията" на мултимодални изображения и Google признава това. Все пак, Flash 2.0 е предназначен да бъде по-малък ИИ модел, който е по-бърз и по-евтин за работа, така че не е "погълнал" цялата масивна информация в интернет. Цялата тази информация заема много място по отношение на броя на параметрите, а повече параметри означава повече изчисления. Вместо това Google обучи Gemini 2.0 Flash, като му предостави подбран набор от данни, който също вероятно включва целеви синтетични данни. В резултат на това моделът не „познава“ всичко визуално за света и самият Google казва, че данните за обучението са „широки и общи, а не абсолютни или пълни“.
Това е просто деликатен начин да се каже, че качеството на изходното изображение не е перфектно - все още. Но има много място за подобрение в бъдеще, за да се включат повече визуални „знания“, тъй като техниките за обучение напредват и изчислителните разходи намаляват. Ако процесът стане подобен на този, който сме виждали с базирани на дифузия ИИ генератори на изображения като Stable Diffusion, Midjourney и Flux, качеството на мултимодалния изход на изображението може да се подобри бързо за кратък период от време.
НОВ КОМЕНТАР
ОЩЕ ОТ КАТЕГОРИЯТА








|
|
Астрономическо събитие на годината: Луната напълно ще закрие Слънцето на 12 август
Свят |OpenAI ще инвестира над 30 милиарда долара в най-големия център за данни с изкуствен интелект в САЩ
Компании |Стажантка в щабквартиранта на NATO в Брюксел е арестувана за шпионаж
Свят |Каналът MS NOW: Вицепрезидентът Джей Ди Ванс се очертава като кандидат за приемник в Белия дом на изборите през 2028 г.
Свят |САЩ удължиха с още месец срока за продажба на активите на „Лукойл“
Енергетика |На днешната дата, 25 юли. Имен ден празнуват Ана, Анна, Анка, Яна
На днешната дата |Тръмп пред Асоциацията на кореспондентите: Шоуто трябва да продължи
Свят |Тръм разпореди пана пред Националния музей на американската история да предупреждават за „лоша информация“
Свят |Заради пожарите: Властите във Великобритания предупредиха туристите за опасността в популярни дестинации
Свят |Времето: Остава ветровито, вълнението на морето ще бъде около 3 бала
България |Държавният глава Илияна Йотова ще се кандидатира за президент
България |45 000 пътници ще използват новите три станции на третата линия на софийското метро
България |Все още ли намалявате цените, за да печелите клиенти? Дайте приоритет на доверието!
Маркетинг |ADVERTORIAL

Две престижни международни отличия за успешния преход на България към плащания в евро

Технополис стартира предварителните поръчки на новите сгъваеми смартфони Samsung Galaxy Z и смарт часовници Galaxy Watch








Коментари
Няма въведени кометари.